RAG #2 - Embedding with AWS Services
Understanding how embeddings can be done with AWS Services

In last article we saw what is Embedding and how its done. In this article we will explore how to create scalable embedding architecture with AWS Services for enterprise grade applications. I will walk you through embedding flow from document storage to embedding creation and storage in a vector database. This setup is serverless, scalable and cost-efficient.
Document Storage in S3
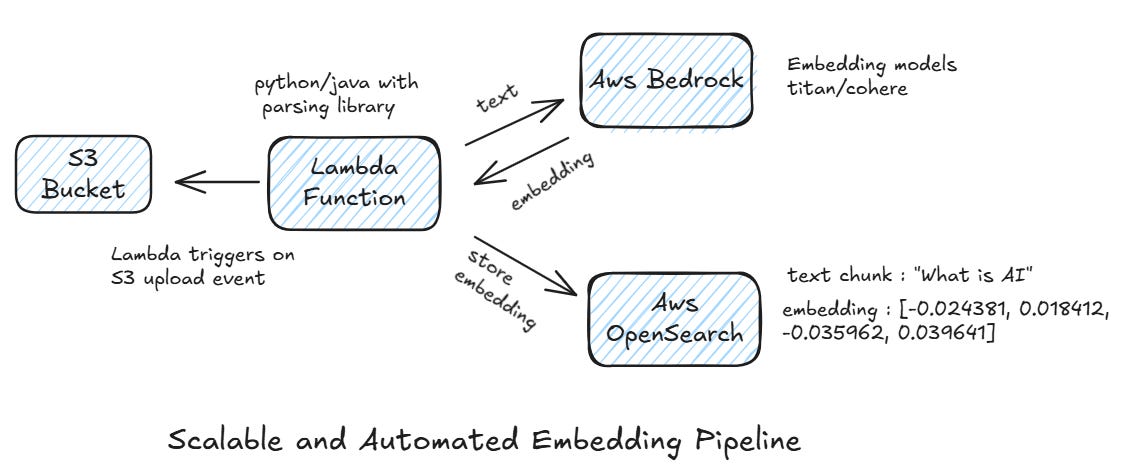
Think of Amazon S3 as your central library for all your source documents — PDFs, Word files, text files, JSON, and more. The moment you upload a file to S3, it doesn’t just sit there. Thanks to S3 event notifications, an automated process kicks off.
Parsing Documents with AWS Lambda
Every time a file lands in S3, Lambda gets notified and immediately starts working. It first checks the document type — is it a PDF, Word doc, or something else? Based on that, it uses the right parsing tools.
For instance, if you’re using Java, you can plug in Apache Tika to extract text from different formats. Once the text is ready, Lambda breaks it down into smaller, meaningful chunks. This step is important — the way you chunk text can affect search accuracy and how quickly you can retrieve results. So, choosing the right chunking strategy is a critical design decision.
Generating Embeddings with Amazon Bedrock
Once the text is parsed and chunked, it’s sent to Amazon Bedrock. Bedrock provides easy API-based access to top-notch embedding models, like:
Amazon Titan Embeddings
Cohere Embeddings
The embedding model transforms each text chunk into a dense vector representation — basically, turning words into numbers the system can understand for semantic search.
Storing Embeddings in a Vector Database
These embeddings, along with useful metadata (like file name, section, or timestamp), are stored in a vector database such as AWS OpenSearch. This database indexes the embeddings and makes them ready fo meaning based search queries.
Automated Flow
Here’s the beauty of it — the whole pipeline runs automatically:
You upload a new document to S3.
Lambda kicks off and parses the file.
Text gets chunked and sent to Bedrock for embeddings.
Embeddings are stored in the vector database, ready for semantic search.
No manual steps, no extra clicks. Just an automated, scalable pipeline ready to turn your documents into searchable knowledge base.